注意:本文中说的日质量大小均为原始日质量文件大小。不是filebeat处理过后的日质量大小
1. filebeat介绍
filebeat最初是基于logstash-forwarder源码的日志数据shipper。Filebeat安装在服务器上作为代理来监视日志目录或特定的日志文件,要么将日志转发到Logstash进行解析,要么发送到Elasticsearch或Redis等组件进行索引
2. filebeat相比于logstash优缺点
filebeat的优点:
- logstash是基于JVM的,资源额外开销十分巨大。filebeat是基于Golang开发的,相当于资源消耗更小,更便捷的logstash
- filebeat是elastic.co公司开发的,官方对filebeat提供了最全面的支持。filebeat的性能非常好,部署简单,是一个非常理想的文件采集工具
- filebeat是基于elastic.co官方提供的libbeat库开发的,代码量不大,我们可以迅速的掌握filebeat,对其进行改造与优化
filebeat的缺点(目前就能想出来这么一个):
filebeat官方提供的功能比较单一,往往无法满足我们的需求(比如说允许写入Redis但不允许从Reids中读出来,若需要读则需要借助logstash这样笨重的组件。不允许写到Metaq一类的中间件做消息存储以缓解ES端的压力)
2. 问题的由来–为什么需要优化filebeat?
filebeat是性能非常出色的文件采集工具,绝大多数的业务日志可以很容易的在1秒内收集至elasticsearch内。但是,个别业务大日志量业务日志无法及时收集
我们做过这样的测试,filebeat运行至Kubernetes集群中,我为filebeat容器分配了“1核心”CPU,其按照官方默认配置写ES的速率低于1M/s
修改了足够多的配置与测试,我们最终优化其性能达到2.3M/s左右。但是这个性能依然无法满足我们部分业务的日质量需求。因而我们这边对filebeat进行源码层面的优化
3. 先来看看filebeat.yml配置文件的优化
方便起见,我直接贴图片了。当然,这些配置只能作为参考。不同的机器性能、网络带宽等适用的配置也不会相同
input端配置调优
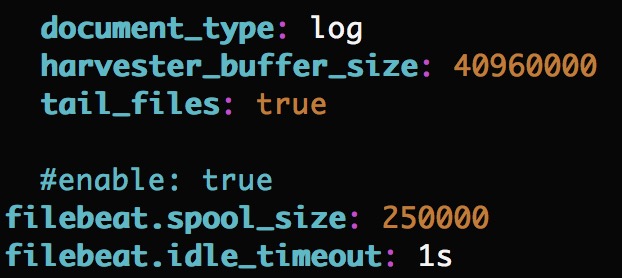
output.elasticsearch端配置调优
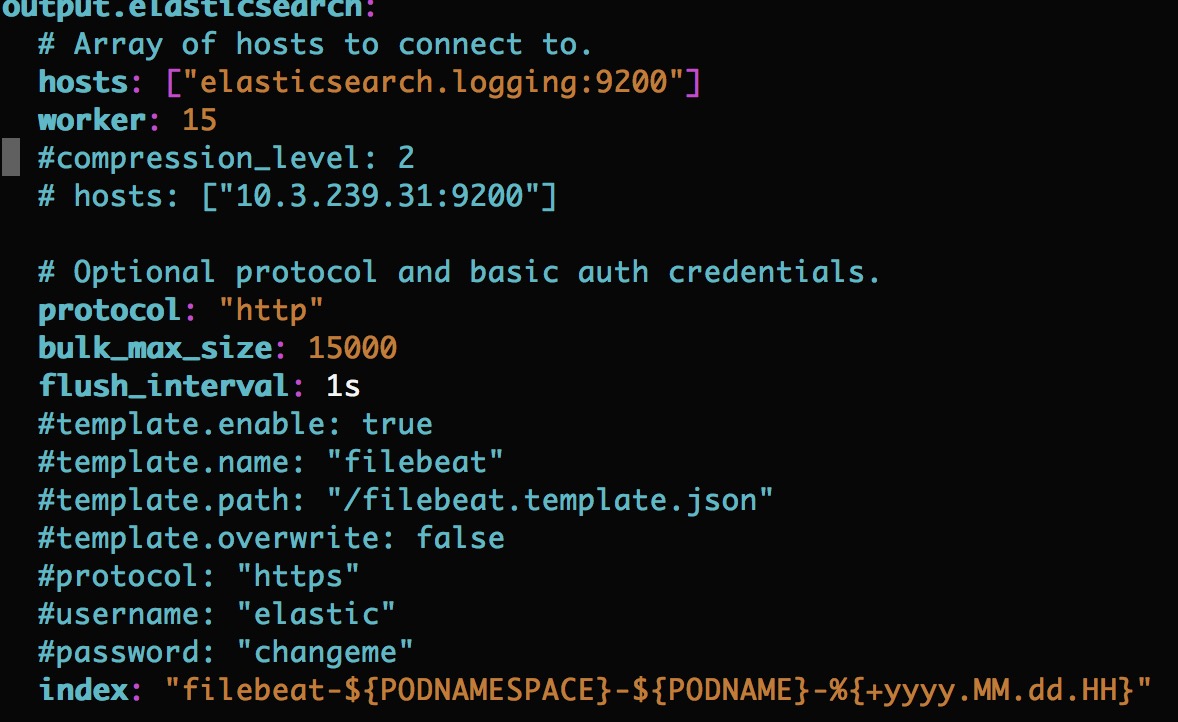
4. filebeat源码层面优化
通过上端的配置优化,filebeat写es的性能有了质的提升,“1核心单位”CPU情况下写ES效率可达2.3M/s。毫无疑问,这个日志量可以满足绝大多数的业务。但是其仍然无法满足我们个别大日志量业务。
通过源码中加log,屏蔽了publish相关的源码,filebeat read to spool的效率高达25.3M/s(1核心单位CPU的容器环境下),由此得知filebeat的性能瓶颈在publish层面。也就是write to es的效率不尽如人意。

每当执行到p.Publish()时,程序会阻塞直至es端收集日志完毕filebeat.spool_size的日志后回馈给filebeat继续publish。由此写入完全跟不上读取的速率。官方说async目前在试验阶段,不建议使用。本人对async方式进行过测试,性能并没有什么显著的增长
我对此部分代码做了如下更改:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
const MAX_PUBLISH_CNT int = 5
func (p *syncLogPublisher) Start() {
// init connection pool
for index := 0; index < MAX_PUBLISH_CNT; index++ {
p.client[index] = p.pub.Connect()
}
p.wg.Add(MAX_PUBLISH_CNT)
runtime.GOMAXPROCS(MAX_PUBLISH_CNT)
for index := 0; index < MAX_PUBLISH_CNT; index++ {
go func(index int) {
defer p.wg.Done()
logp.Info("Start sending events to output")
defer logp.Debug("publisher", "Shutting down sync publisher")
// logp.Info("index: %d", index)
for {
err := p.Publish(index)
if err != nil {
return
}
}
} (index)
}
}
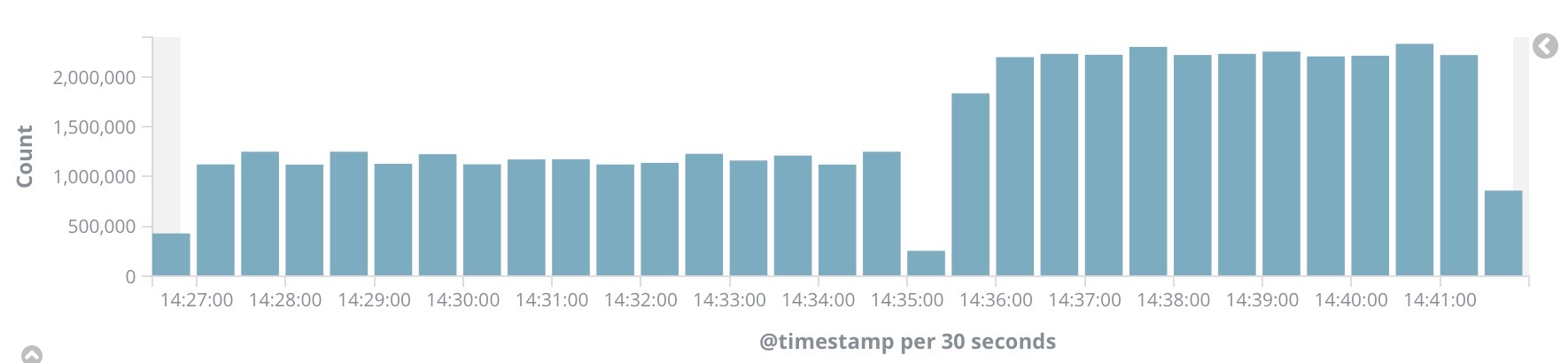
由于golang的便捷性以及filebeat本身出色的设计,保证了我此处的改动没有线程安全问题。效果的提升是显而易见的,性能在原先的基础上提升了100%,如下图所示:
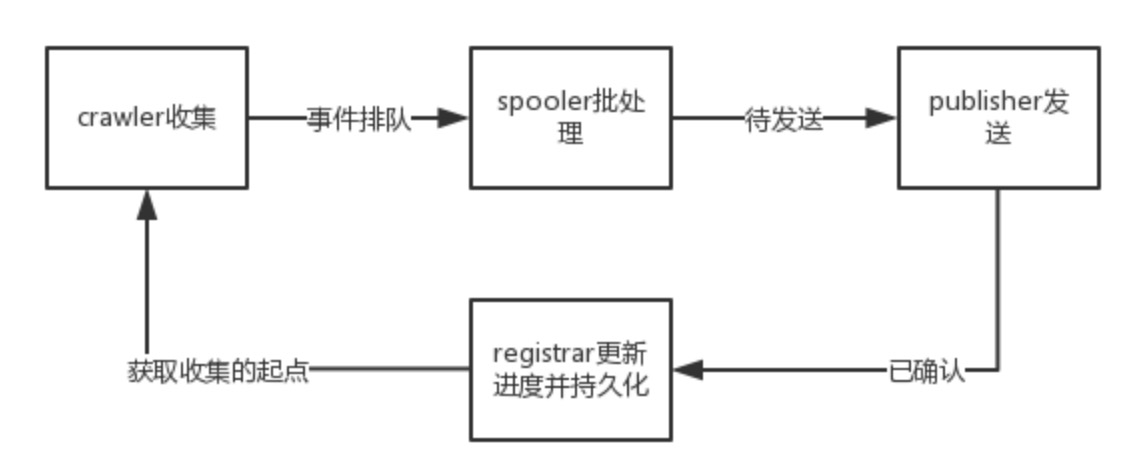
为什么可以这么写?那么在此聊一聊filebeat的几个关键点:
- 一次Publish,上传多少行的日志量?这个这个值在filebeat.spool_size中定义
- Publish中做了什么?启动worker个协程推送filebeat.spool_size行日志到ES中,阻塞,等待所有协程推送完毕后继续执行。因此,上部分代码不会影响此处
- offset问题,offset会不会导致不同publish线程发送重复数据?Harvester组件对offset进行修改(读日志组件,在Publish)之前,因此offset不会影响日志publish重复问题
5. 进一步可优化项
- filebeat.template-es2x.json
- filebeat.template.json
减少filebeat为日志添加的不必要的字段。性能预估可再度提升50%。这样足够满足了我们公司的所有业务的日志读取问题(6.5M/s/POD的日质拉取速率)
6. 展望:还能为filebeat做些什么?
随着越来越多的业务接入,ES毫无疑问会到达瓶颈,我们不能仅仅通过单一的水平扩容来解决es性能瓶颈问题。可以考虑Redis或Metaq这类组件作为中间件存储。可以良好的利用ES资源,避免流量高峰期ES陷入性能瓶颈。流量低峰时不必要的资源浪费问题。这些均可在源码层面对filebeat进行功能扩充