1.ISSUE: filebeat文件描述符溢出
问题的描述:使用filebeat跑了过节的一段时间,线上环境磁盘报警。删掉日志后,发现剩余的磁盘容量仍不客观。使用lsof命令分析后。结果如下图所示:
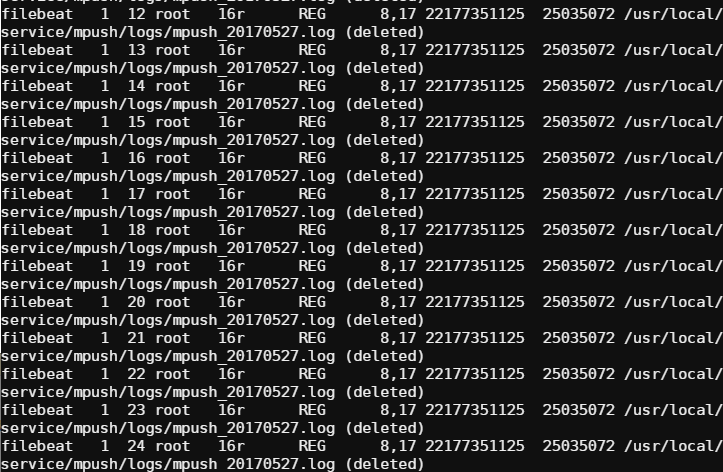
产生这样的原因是因为后端elasticsearch压力过大挂掉后,filebeat代码整个会阻塞在publisher,不断往elasticsearch推数据、不断的失败。为什么会不断的重复推送?我们再次看看filebeat的源码:
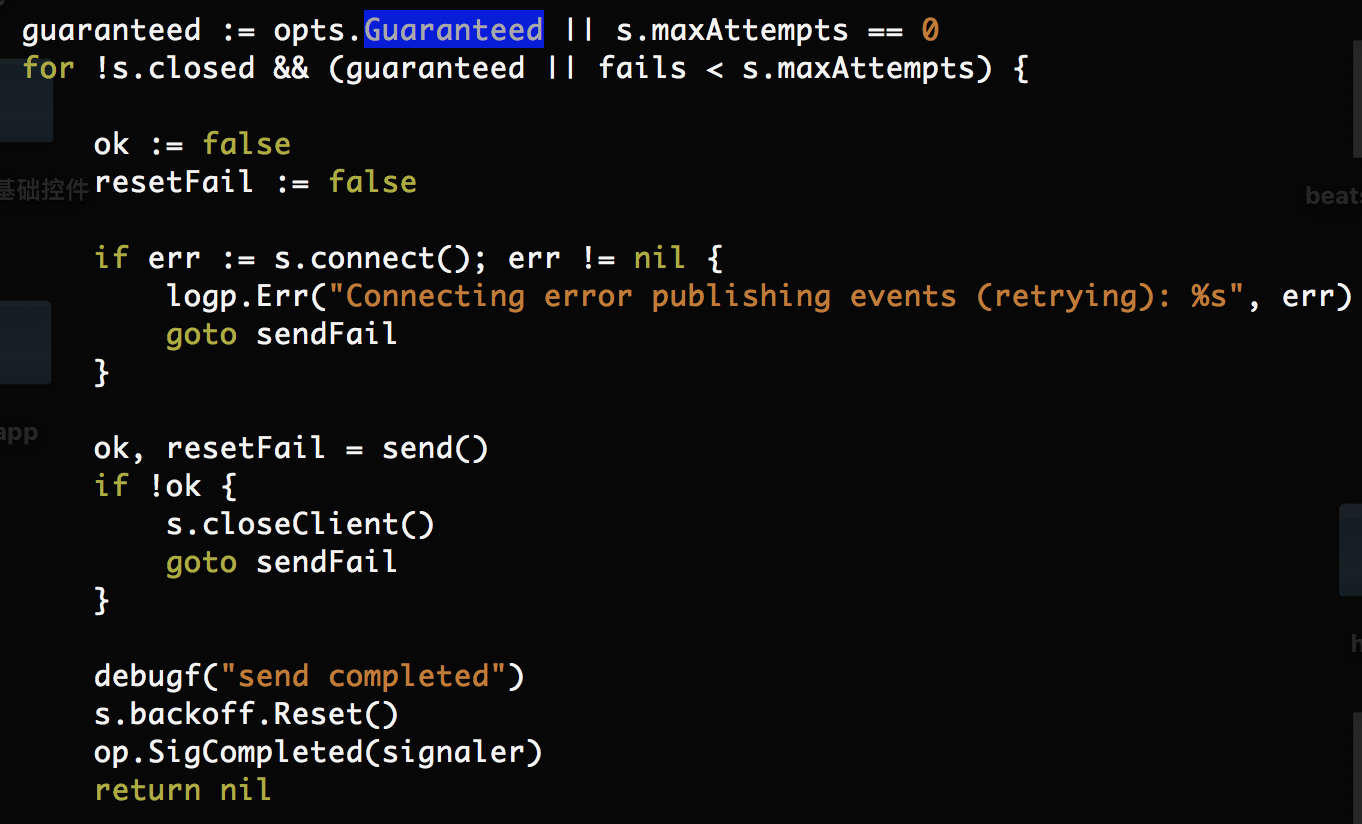
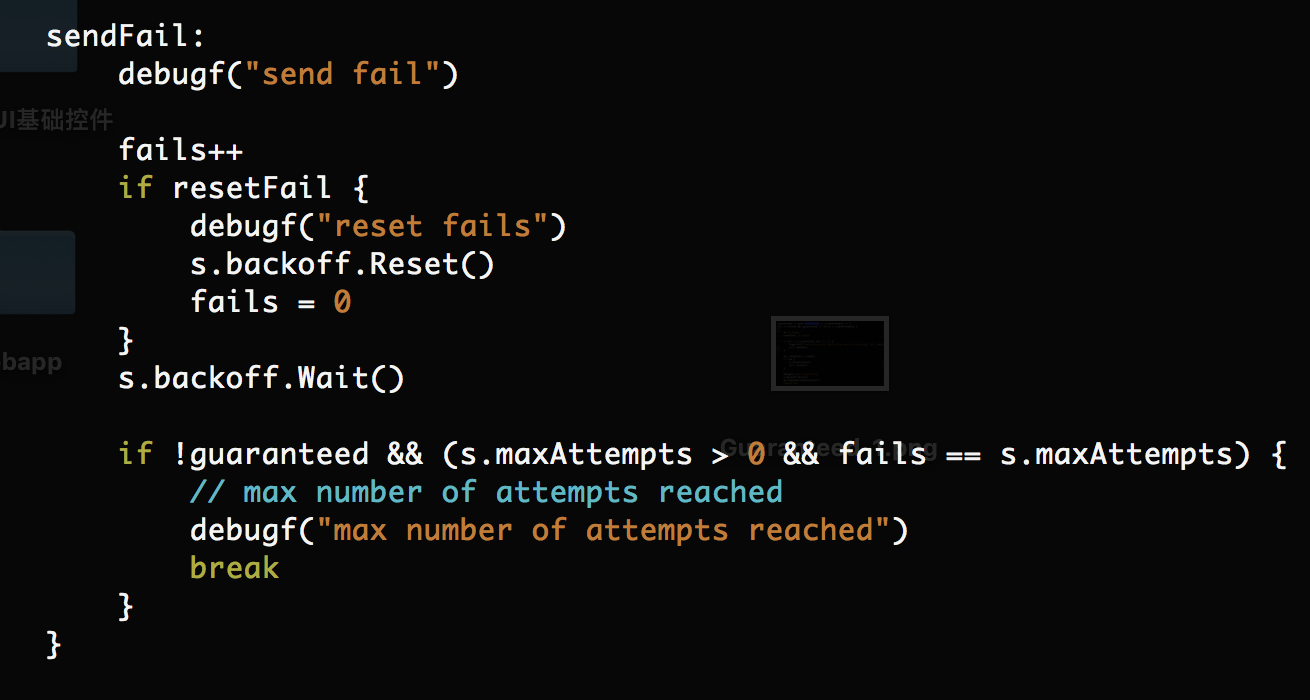
上面的两段源码来源于:/beats/libbeat/outputs/mode/single/single.go
代码中可以看出,当发送失败时,程序会反复重试,当Guaranteed为false时,会反复publish到达maxAttempts时,丢弃bulk-size单位数据。继续推送新的数据。然而:

上图可知,因为源码写死的Guaranteed为true。官方的源码希望filebeat不丢弃数据,永久反复推送尚未成功发送的数据,直至发送成功为止。因此:
- 后端Elasticsearch阻塞导致filebeat的publisher阻塞
- filebeat的publisher阻塞导致数据一直不能成功发送完,发送不完spool_size,导致spooler不会主动通知prospector,prospector因此也不会通知harvester重新拉取spool_size单位的数据
- harvester阻塞后无法读日志文件,无法通过errCheck来关闭删除掉的文件,导致删除的日志文件描述符仍被占用,耗费磁盘空间
2. filebeat文件描述符溢出解决方法
- 改写Guaranteed为false
方案的优点:高效,从改写源码到编译成可执行二进制文件仅需1分钟
缺点:官方不推荐的做法,Guaranteed选项官方并未提供配置文件配置的方式。如需要需自己手动添加;如果spool_size大小远超builk_size大小,maxAttemp设置的很大。这样,释放文件fd可能及其的漫长。时长粗略计算公式:(spoll_size / builk_size) * 5 * time.Second * maxAttemp。这样修改后的filebeat会丢失部分数据。
- 基于prospector点优化
prospector就像是一个桥梁,读端(harvester、spooler等)与写端(publisher)之间交互的桥梁。prospector定期会判断各个harvester的状态。当文件已被删除时,其会根据需求将相应的harvester清除掉。当匹配的规则中匹配到了新的日志文件,prospector会启动新的harvester进行日志的拉取。因此在修改prospector等同于在源头对harvester进行修改。接下来的篇章对此进行详细剖析。
3. 非阻塞prospector实现
harvester端阻塞时,正常情况下prospector端是不会被阻塞的,它仍兢兢业业的每隔scan_frequency的时间检查一次harvester的状态以及判断当前日志文件有无变更(增加、删除等问题)。
什么时候prospector会被阻塞呢?答案是:有新节点亦或者是harvester监听的日志文件发生rename或者remove事件时会发生阻塞。阻塞后的prospector等待一个信号。如下图所示:
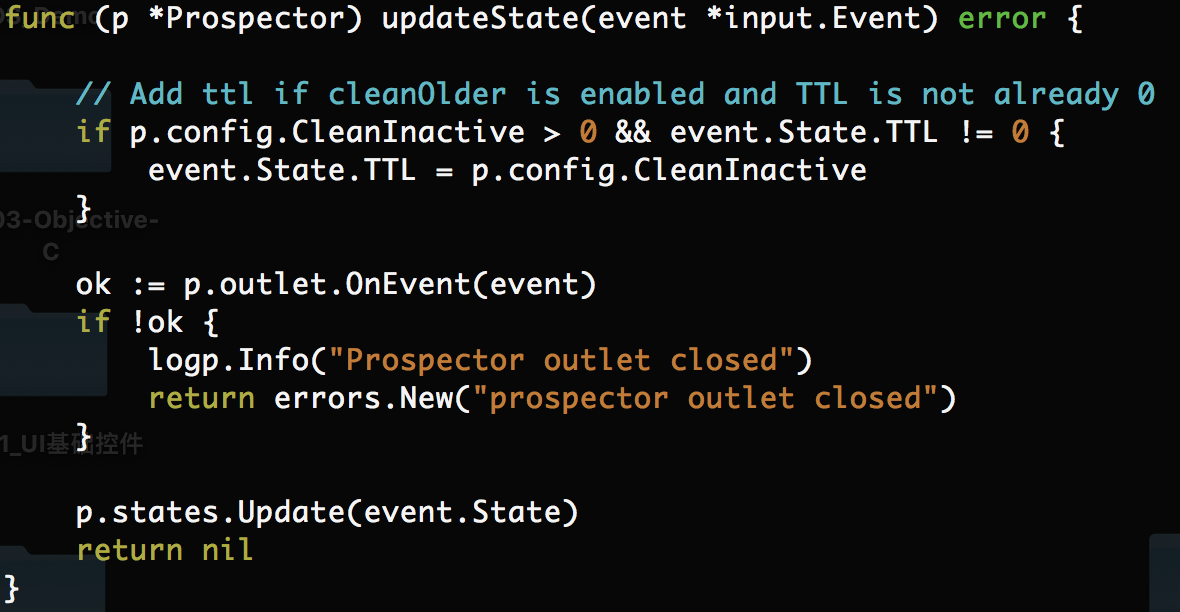
prospector会阻塞在OnEvent(event)。然而OnEvent的存在并没有实质性的作用,而我们希望的是prospector做到完全的非w阻塞。即便filebeat后端服务完全阻塞,其也能感知监听的日志文件有无变更(rename或remove或add)。而add时,我们希望prospector为我们生成新的harvester,更新prospector的状态。如果不能及时的更新状态,会影响harvester删除操作的正常运行。为此我们重新实现了一个非阻塞的updateState方法:
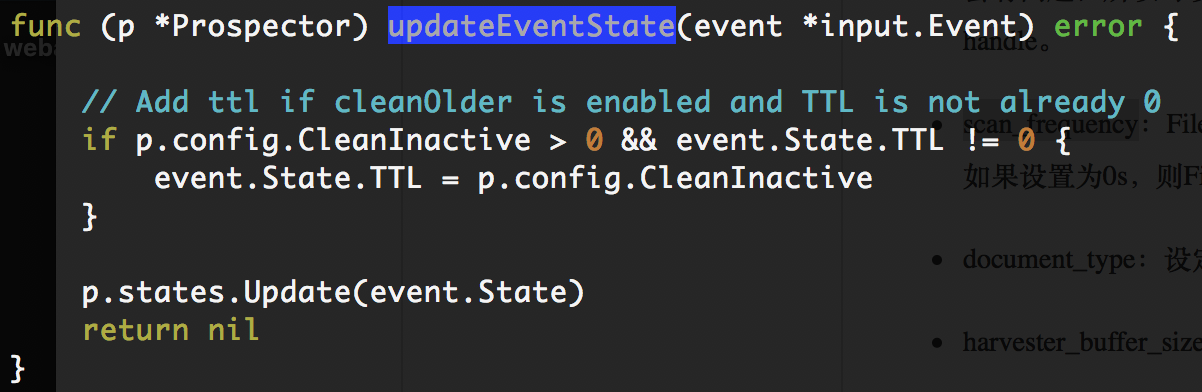
4. 从filebeat5.2.2迁移现有改动到filebeat5.3.0
为什么我们需要filebeat5.3.0?请看下面这个结构体(filebeat5.3.0)特有
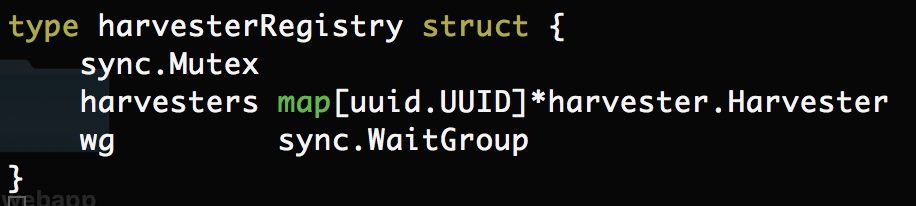
当filebeat5.2.2阻塞时,要想解决文件描述符溢出问题。在prospector中需要找到日志文件已被删除的harvester是十分困难的。因为prospector中并没有对harvester进行上图这样的一个统一的管理。我们想拿到指定的harvester相当的繁琐。升级到filebeat5.3.0官方的源码为我们实现了我们所期望的功能。
5. Harvester删除操作
在Prospector初始化时起一个GoRoutine定期执行Harvester-Check工作,检查Harvester监听的日志有没有没删除,如果被删除,则关闭文件描述符,关闭Harvester。解决文件描述符溢出的BUG
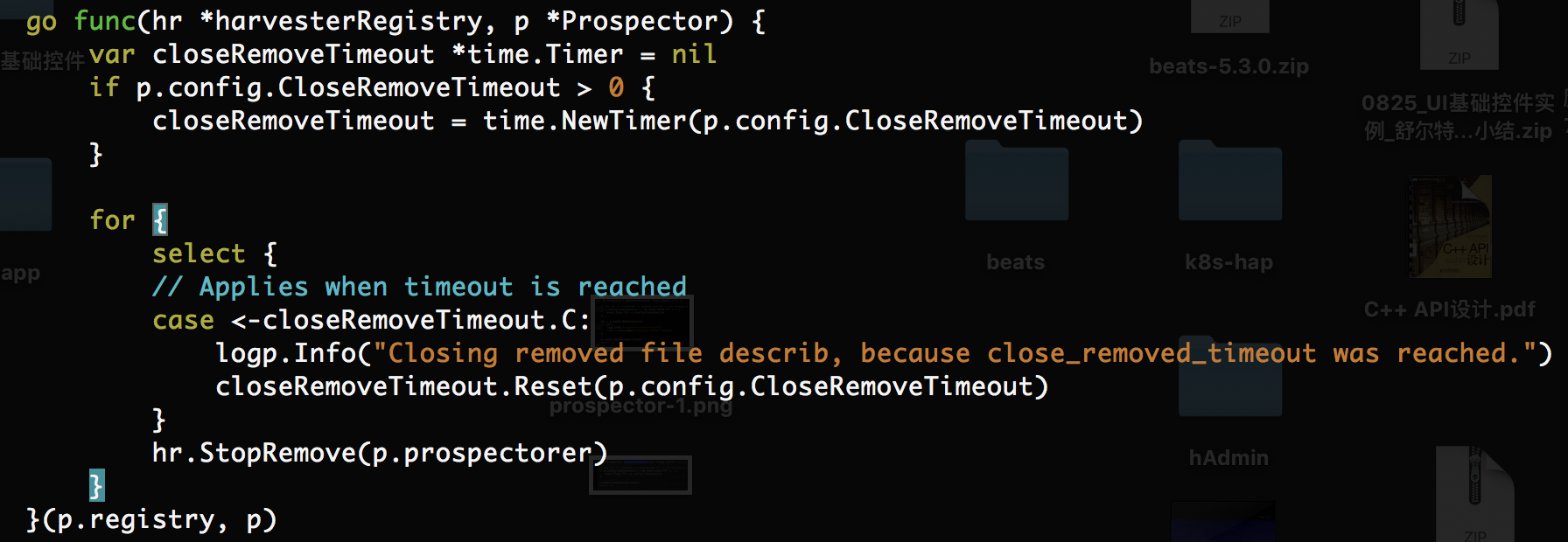
每隔closeRemoveTimeout的时间将会执行一次StopRemove方法
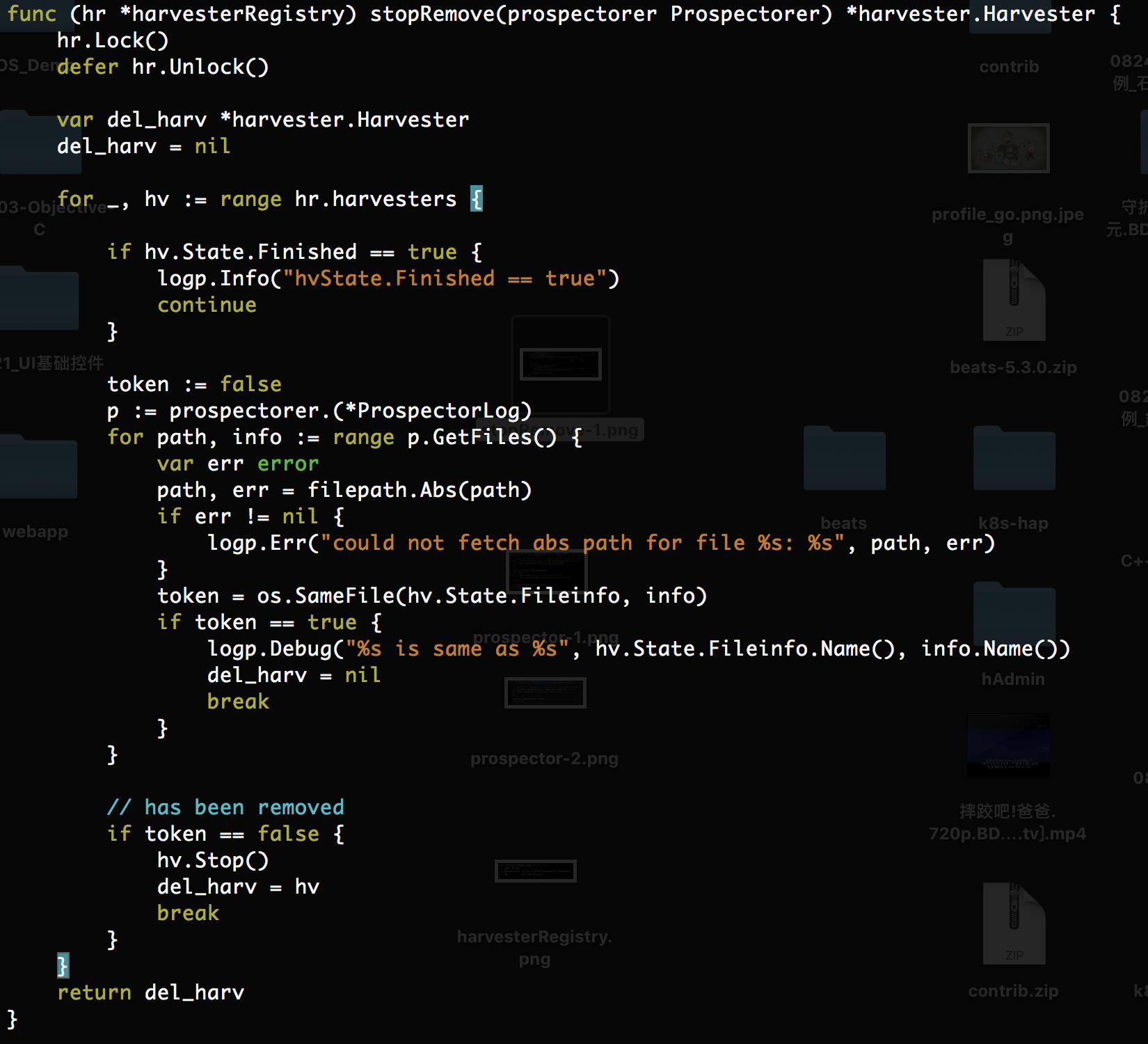
这样我们不必担心filebeat阻塞,Harvester不清楚导致文件描述符溢出占用磁盘空间的问题。上面的代码为本次改动的核心代码。细节请参考(https://github.com/Lpc-win32/beats)
-
Previous
filebeat to elasticsearch针对于filebeat端性能优化--性能提升230% -
Next
kubernetes集群自定义指标扩容缩容hpa-custom-controller的原理及实现