1. k8s-hpa与我们的hpa-custom-controller
1.1 为什么需要自动扩容与缩容?
一个业务可能存在这样的问题:一天之中绝大多数的时间的流量都很平滑,每秒的qps比较低,cpu使用率常年低于20%。但因为某种原因(工人每天6点下班,某某活动)会存在一个海量请求汇聚的时间段。cpu瞬间提升至80%以上,接收队列与发送队列满,超时丢包情况频频发生。物理机或虚拟机该如何应对这种问题?申请大量的机器以应对高并发请求量时的网络冲击。成本呢?自然会比较高。
hpa组件在kubernetes中地位超然,其控制kubernetes集群中pod的自动扩容与缩容。我们在启动一套业务的时候,根据业务的需求配置cpu的request以及limit、最小副本数以及最大副本数(pod为单位)、以及扩容缩容的比率(在k8s中该扩容的比率和缩容的比率是相同的)。因此,避免了虚拟机会遇到的成本大幅度浪费的问题。当流量增高,副本数扩大,流量降低后,副本数缩小。
1.2 k8s-hpa存在的问题
1.2.1 配置不合理导致k8s-hpa无法按照预期的方式扩容缩容
kubernetes 5.2版本中,kubernetes仅针对cpu指标支持自动扩容缩容。而且其扩容缩容针对的是pod为单位的。但是在每个pod中通常会有多个容器。再生产环境中我们就遇到过这样的问题:
server-xxxx这个pod中存在两个容器:
1.业务容器(1 core CPU)
2.filebeat日志拉取容器(1 core CPU)
配置的pod扩容缩容的cpu比率为70%
问题就这样发生了。业务容器的CPU已经使用了100%,但是因为没有开日志的缘故,导致filebeat没有日志可以拉取,cpu的使用率几乎为0。以k8s扩容的标准来看当前的pod的cpu使用率为50%,于是不满足扩容的条件。(虽然k8s的扩容缩容算法不是这样的,但是这么理解是没有错的。我会在后面贴出扩容缩容的算法)。我们不能保证业务方能够清楚的知晓他们的各个业务的cpu使用情况。因此这种配置不合理导致不能正常扩容缩容的问题会比较容易的发生。
k8s计算期望副本数的算法:(total(pod_cpu_usage) / pod扩容缩容百分比)向上取整
1.2.2 k8s的扩容和缩容百分比相同,可能会产生频繁扩容缩容的问题
举个例子:(total(pod_cpu_usage) / pod扩容缩容百分比)向上取整一会儿算出值为4(3.01),过一会儿算出值为3(2.99)。这样会造成频繁扩容缩容的问题。通常业务方更期望的并不是绝对的尽可能节省成本,而是业务在运行过程中尽可能的稳定。因此,缩容的阈值应当低于扩容的阈值以避免频繁的扩容缩容问题
1.2.3 k8s仅支持cpu指标的自动扩容
往往一个业务的负载并不仅仅只凭cpu负载决定,其取决于多种维度:QPS,网络因素,I/O,内存以及业务指标等等。k8s 6版本官方声明支持自定义指标。但是这个自定义指标依然存在局限性,无法友好的兼容到业务自定义指标
1.3 hpa-custom-controller依赖的组件
- kubernetes(用于通告api-server执行扩容缩容以及单点问题)
- promethues(用于提取k8s指标以及业务指标)
- etcd(k-v数据库,存储扩容相关)
1.3.1 etcd简介
etcd是用于共享配置和服务发现的分布式,一致性的KV存储系统。etcd是CoreOS公司发起的一个开源项目,授权协议为Apache。
相比于Zookeeper,etcd无论是在维护,使用,安全性还是设计等方面都更为出色。

2. hpa-custom-controller介绍与实现
2.1 hpa-custom-controller介绍
hpa-custom-controller采用go语言编写。目的用于更好的兼容k8s、promethues、etcd等golang编写的组件(高可用组件使用了k8s-pkg中提供的package完成)
hpa-custom-controller源码地址: Lpc-win32/hpa-custom-controller
由于本人是golang的初学者,代码里写的比较low的地方,欢迎直接喷出来~~在此感谢各位
2.2 hpa-custom-controller的模块
主要分为collector(收集)、controller(控制)、high_available(高可用)三个大模块
2.3 collector
用户在k8s集群上线一个业务时,会配置一些hpa相关的信息。这些信息我们会存储至etcd中。而collector的作用就在于定期从etcd中拉取配置,汇总并递交给controller处理。etcd存储的内容例子如下:
1
2
3
4
5
6
7
8
9
10
11
minreplicas: 2
maxreplicas: 4
name: "nginx-test" # deployment name
namespace: "default"
scalermetrics:
container_memory_usage_bytes{pod_name=~"nginx-test.*",image=~".*auth/auth.*"}: # promethues查询语句
minscaler: 50.0
maxscaler: 70.0
container_cpu_usage_bytes{pod_name=~"nginx-test.*",image=~".*auth/auth.*"}:
minscaler: 50.0
maxscaler: 70.0
这样看起来,相信大家心中已经比较明晰了。
其中值得一提的是:我们通过http/https请求etcd并不能保证每次都能请求成功。因此我们维护了一个map保存上一次Spec集合。如果本次取到数据,则更新map,没有取到数据则取上一次数据,如果依然取不出,则放弃。此处效率并不高,估计这几天就会改掉。(不必特别在意此处…)
这样做有什么好处?我们的缩容是有时间限制的,默认规定是5分钟的时间。如果低于5分钟仍然达到可缩容的条件,那么仍然不可缩容。因此为了不让hpa-custom-controller组件误以为需要缩容的server已经下线,故有了这样的策略。
2.4 controller(核心)
controller收到collector传递过来的Spec(上面的一段示例数据,我们称呼为Spec)数组时,会每一个Spec启动一个goroutine去执行控制层面的操作。操作步骤大体如下:
- 判断当前副本数是否满足minreplicas、maxreplicas。若不满足,直接scale
- 请求promethues查询指标的值(array),依次比较每个值。当前指标值超出maxscaler则计数器加一。如果计数器的值大于0,则期望的副本数为当前副本数+计数器的值。当计数器为0,则考虑缩容的问题。缩容的算法与k8s扩容缩容算法一致: (total(pod_cpu_usage) / pod扩容缩容百分比)向上取整
- 等待全部Spec处理完成后,函数返回
问题:为什么一个pod的指标超出就要扩容?因为由于node机器型号不同、网络带宽不一致、程序编码问题导致的每台机器“不绝对”的负载均衡。同一个业务有些pod已经达到了90%但是有的pod只在60%徘徊的情况并不少见。因此尽可能优先的保证扩容是多数业务方的需求
2.5 high_available
hpa-custom-controller组件在整个k8s集群中的作用是巨大的,如果hpa-custom-controller停止工作会牵连整个k8s集群的自动扩容情况。因此必须保证high_available。但是,hpa-custom-controller必须只能同一时间一个pod工作。因此我们借助k8s实现了一套leader-election(在contrib/election开源项目的基础上定制)。
hpa-custom-controller在我们的集群中是随k8s-master启动的(将hpa-custom-controller.yaml置于/etc/kubernetes/manifests路径下),会根据提供的election-id选举出当前的leader,leader工作时,非leader不工作。leader挂掉时,k8s-apiserver会重新通知新的leader开始工作,核心源码如下图所示:
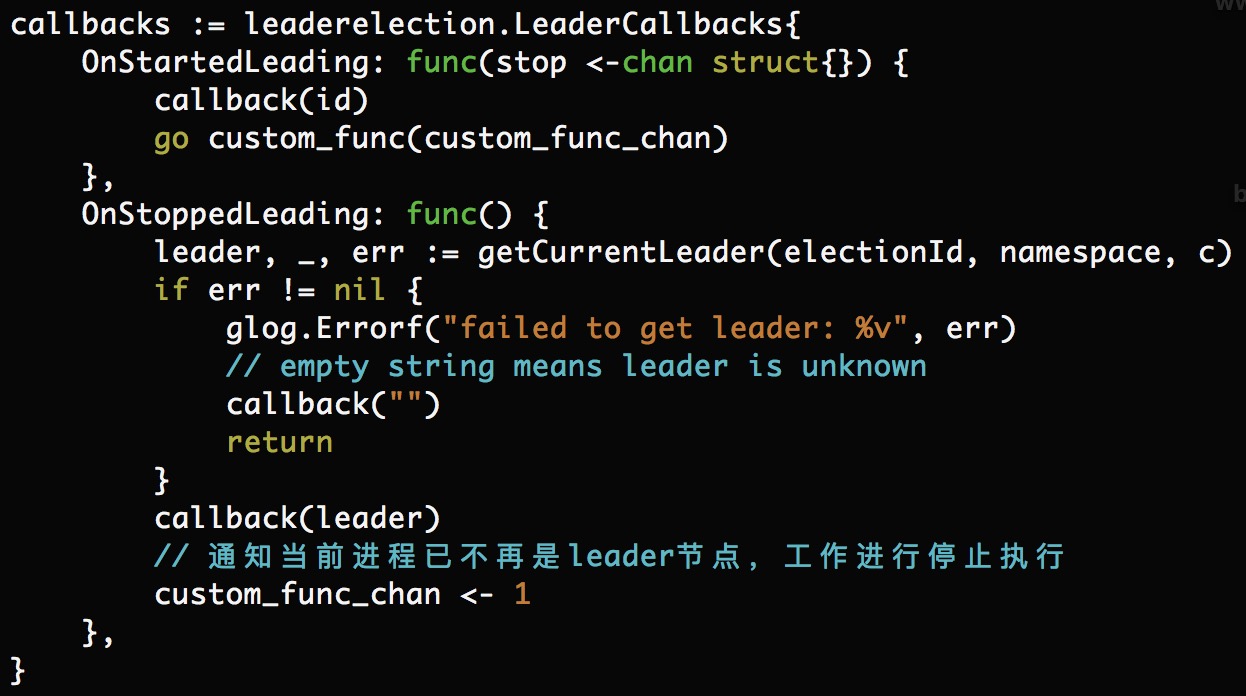
缺点:正因这个问题,hpa-custom-controller组件仅能运行在k8s集群容器环境中。不可直接运行在物理机与虚拟机上
3. 总结
- 这是一个beta版本的blog,来介绍hpa-custom-controller
- hpa-custom-controller强依赖于promethues组件,但是promethues在指标量过大时,会存在“不存”指标等问题。后面我会介绍一下promethues优化的文章
- hpa-custom-controller代码中存在一些低效环节,我会尽快优化。同时也感谢大家的帮助
==来自:http://pancakeliu.github.io/2017/06/22/k8s-hpa-custom-controller-achieve/==